
The game-changing applications of neuromorphic high-speed vision


In a very short time, the digital world has become dominated by visual data. Cameras are everywhere, pumping zettabytes of data into phones, cars, tablets, and robots. However, this data is not all created equal. We can categorise digital visual data in the following ways:
1) Static Vision
Static vision entails huge repositories of pre-recorded images and videos, of the type in your Instagram feed. 1.4 trillion photos were taken in 2020, of which 85% were on smartphones. While this static repository of data is mind-boggling, it represents a saturating market.
2) Reactive Vision
After capture, static data can be analysed and acted on by computers using pattern recognition algorithms (what is currently termed “AI”). The analysis could occur soon after capture (e.g. surveillance systems), or much later (e.g. auto-tagging faces of your friends on Facebook). Currently, there is a huge global technology competition in creating systems that can perform such image recognition tasks as quickly and efficiently as possible.
3) Dynamic Vision
Dynamic vision systems demand a real-time response, putting hard constraints on the acceptable required computing power, energy efficiency and time delay. Common examples include Instagram augmented reality (AR) filters, autonomous driver assistance systems (ADAS), and industrial automation robots. Often, these systems do not store most of the data that is captured: they process it, use the results immediately, and only save key features extracted from the data.
Speed & Efficiency
Dynamic vision systems are far more challenging to build than static or reactive systems. However, the applications that they enable – particularly in robotics – promise to change our world just as fundamentally as earlier revolutions in personal computing and the Internet. The trillion-dollar question is: how can we build such systems to be as fast and as efficient as possible?
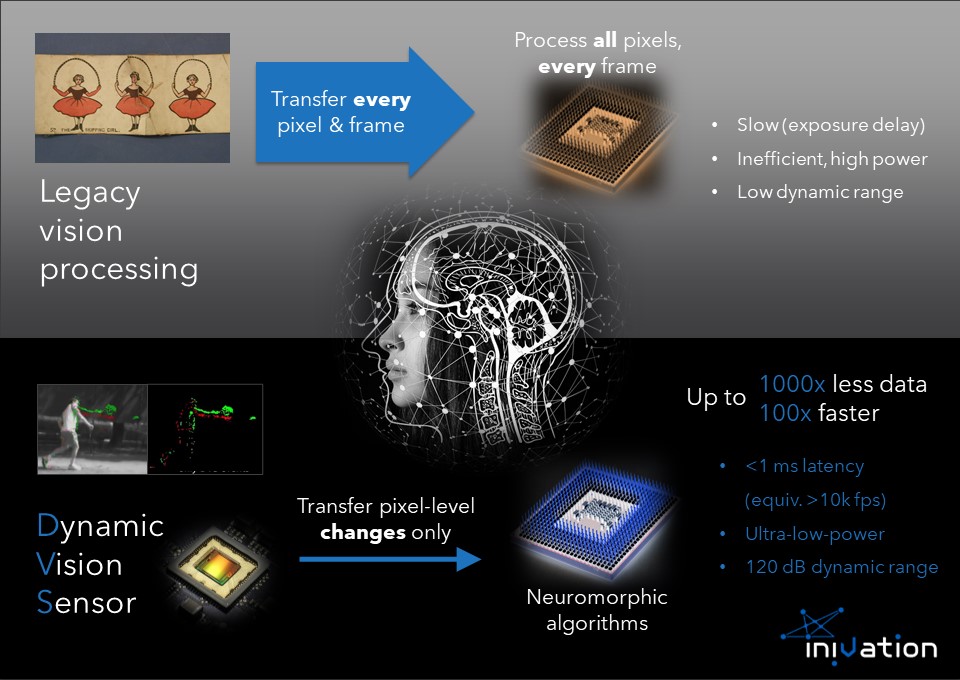
To date, almost all dynamic vision systems can be classified as ‘reactive vision systems on steroids’. Pictures or videos are captured, and then sent to a computer where various algorithms are applied. This pipeline of capture – transfer – process has been unchanged since the beginning of photography and computing. However, it is incredibly slow and inefficient, because the processing is treated as an afterthought rather than as an integral part of the vision process. Furthermore, cameras have fixed exposure times, resulting in difficulties with capturing high-dynamic range scenes.
Neuromorphic Engineering
How can we improve this state of affairs? One way is to take inspiration from the fastest, most powerful vision system available – our own human visual system. While certain animals can beat us at some visual tasks, we are unique in our ability to understand the visual world. Our eyes and brain enable us to model the world in high resolution in full colour, with excellent 3D perception and highly flexible operation in almost all Earth environments from bright sunshine to dark caves and even underwater. The field of neuromorphic engineering set out to extract key principles of human computation, using visual processing as a first target.
The key insights gained included the following:
- The retina does not take pictures; it responds primarily to changes in the scene. This feature is probably useful from a survival point of view, since important features of the environment are most likely to be things that are moving.
- Each eye has 100 million receptors, which produce impulses (“spikes”) that are processed by neural networks in the eye itself to produce a very compact representation of what the eye is seeing: edges, forms, and so on.
- Processed data from the 100 million receptors is sent via the optic nerve to the visual cortex via a very low-bandwidth connection, estimated to be only around 1 MB/s. (For comparison, your 5G phone can transmit up to around 100 MB/s.) This huge data reduction means that, with the right data formats and processing algorithms, large increases in speed and efficiency are possible.
iniVation
One company planning to convert these insights into solutions that can change the world is iniVation. The Zurich-based company has built on these insights to create its Dynamic Vision Sensor (DVS) technology. The founders of iniVation include some of the key pioneers of the field who helped to create the field of neuromorphic engineering in the 1980s and 1990s.
In the DVS technology that iniVation has created, every pixel works independently from the other pixels in analog mode, providing an event-based stream of changes as the raw sensor output. The DVS offers several performance advantages over conventional machine vision systems, including:
- Low latency (<0.1 to 1 ms), since there is no waiting for fixed frame exposures, leading to much faster camera response times.
- High dynamic range (>120 dB), due to the logarithmic response of the pixel.
- Lower computation and data storage requirements.
- Ultra-low power consumption enabling devices with always-on battery life.
Applying DVS Technology
There are many application areas in which the DVS technology developed by iniVation has clear advantages over conventional machine vision solutions. Because of this, prominent deep tech investors have started to take serious interest in the field of neuromorphic vision.
A few examples of applications include the following:
- Ultra-fast eye tracking for next-generation VR/AR headsets. iniVation recently launched Foveator™, an extreme-performance low-power mobile eye tracking system.
- Ultra-fast 3D laser profiling for faster robotic factory operations including gluing, welding, etc. To address this market, iniVation has launched the DVL-5000, the world’s first high-speed neuromorphic laser profiler.
- Rapid real-time visual positioning systems for robots, vehicles, spacecraft, and other devices.
- Autonomous vehicle vision systems for detecting obstacles faster in challenging lighting conditions, where current cameras often fail.

On-Sensor Processing Technology
As well as near-term applications, iniVation is also working on future generations of event-based sensors with additional features. Many of these are inspired by how the retina operates and communicates with the brain. The key motivation for this is to move as much of the data processing into the sensor as possible, to reduce data transmission and subsequent data-processing requirements.
In one example, iniVation has demonstrated an on-sensor processing technology which links together adjacent pixels so that neighbouring events which occur approximately simultaneously can be transmitted as a single event, reducing noise and data bandwidth requirements. Another newer development enabled iniVation to capture events and conventional frames using the same sensor, allowing customers to upgrade their existing software systems progressively, thus protecting their legacy investments.
What is clear is that we are at the beginning of new era in creating mobile, intelligent vision machines. These machines will understand and respond to the visual world, with a level of speed, efficiency, and autonomy that will approach and even exceed our own. The value that will be unlocked is truly immense.